ナレッジグラフ / Knowledge Graph – Logo
Neon-gradient network of nodes/edges with S–P→O triples, ontology bracket, embedding grid, and reasoning flow on dark #050913.
GRAPH
S
P
O
TRIPLE
Class
Prop
ONTOLOGY
EMBED / ADJ
QUERY
REASONING
SEMANTIC NETWORKS — ONTOLOGY × TRIPLES × EMBEDDINGS
ナレッジグラフ
ナレッジグラフ
S–P→O のトリプルとオントロジーで知識を接続し、推論へ
Google検索のナレッジグラフ(Knowledge Graph(KG))を、公開された 論文・特許 を拠り所に、仕組みと実装上の要点を噛み砕いて解説します。
ナレッジグラフとは
Googleのナレッジグラフとは、ウェブ上の文書から実体(エンティティ )と関係 を抽出・統合した大規模知識ベースです。
2012年に「things, not strings(文字列ではなく「もの」)」として導入され、検索を語句一致 から意味理解(実体理解)へ移行させる中核。
Googleナレッジグラフ
things, not strings
文字列ではなく「もの」として理解する – 2012年導入
従来の検索
語句一致(文字列マッチング)
“東京スカイツリー 高さ”
“634メートル タワー”
“墨田区 観光地”
“2012年 開業”
“電波塔 放送”
“東武鉄道 建設”
バラバラの文字列情報
実体抽出・統合
Extract & Integrate
ナレッジグラフ
意味理解・実体理解
東京スカイツリー
[建築物]
634m
[高さ]
墨田区
[所在地]
2012年
[開業年]
電波塔
[用途]
東武鉄道
[事業者]
観光地
[分類]
東京都
[都道府県]
日本一
[記録]
高さ
所在地
開業
機能
建設
種別
都道府県
国内記録
ウェブ上の文書から実体と関係を抽出・統合
ウィキペディア
ニュースサイト
公式サイト
地図データ
データベース
ナレッジグラフの規模感(公表値)
2020年時点で50億エンティティ ・5,000億ファクト 超を保持(Google公式)。
引用;https://blog.google/products/search/about-knowledge-graph-and-knowledge-panels/
ナレッジグラフ構築のパイプライン(概観)
(1)データ源 (オープン/ライセンスDB、構造化マークアップ、ウェブ自動抽出)
(2)正規化と同一性解決 (Entity Resolution)
(3)スキーマ整合 (型・属性の割り付け)
(4)確率的データ融合と信頼度推定 (Knowledge Vault, KBT)
(5)格納・インデクシング
クエリ理解とパネル生成 (特許で説明されるテンプレート・文脈最適化)。
ナレッジグラフの構築パイプライン
Knowledge Graph Construction Pipeline
(1) データ源
Data Sources
• オープン/ライセンスDB
• 構造化マークアップ
• ウェブ自動抽出
(2) 正規化と同一性解決
Entity Resolution
データクレンジング
エンティティ 統合
重複排除処理
(3) スキーマ整合
Schema Alignment
型の割り付け
属性の割り付け
オントロジーマッピング
(4) 確率的データ融合と信頼度推定
Probabilistic Data Fusion
Knowledge Vault
KBT (Knowledge Base Trust)
信頼度スコアリング
(5) 格納・インデクシング
Storage & Indexing
グラフDB格納
インデックス構築
キャッシュ最適化
クエリ理解とパネル生成
Query Understanding & Panel Generation
特許で説明されるテンプレート
文脈最適化アルゴリズム
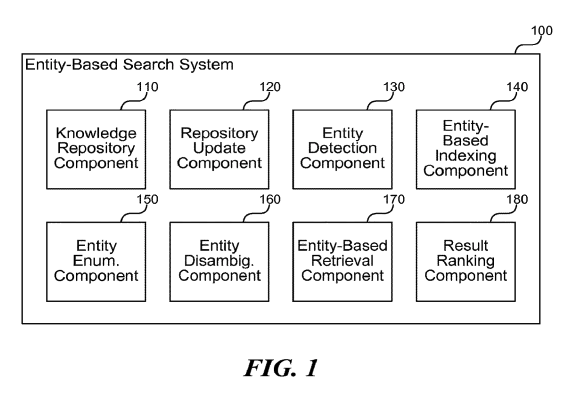
動的パネル構成とレンダリング
Feedback Loop
Google検索とナレッジグラフ
クエリからエンティティ を検出・曖昧性解消 し、関係(述語)を推定、ナレッジパネル や答えを動的に合成します。これは知見の表示順位・項目選択 を含め、複数のGoogle特許に詳細があります。
「ナレッジグラフ」はGoogle検索をどう変えたのか
Googleは2012年に「things, not strings(文字列ではなく「もの」)」という合言葉とともにナレッジグラフを公開し、検索が語句一致から実体理解へ移行することを明確にしました。
これは、人・場所・組織・作品といったエンティティ と、その間の関係を機械が把握し、検索結果に即応するための大規模知識基盤です。公式発表は、ランドマークや人物、映画などを「もの」として理解し、文脈に応じた情報を即座に返す狙いを示しています。
ナレッジグラフはGoogle検索をどう変えたのか
“things, not strings” — Google 2012
従来:文字列マッチング
語句一致による検索
“東京タワー 高さ 展望台”
キーワードごとに分解:
“東京タワー”
“高さ”
“展望台”
検索結果:
▸ 「東京タワー」を含むページ
12,543件のマッチ
▸ 「高さ」というキーワードを含む文書
8,921件のマッチ
▸ 「展望台」を含むテキスト
5,678件のマッチ
制限事項
✗ エンティティ 間の関係を理解できない
✗ 文脈や意味を把握できない
✗ 表面的なキーワードマッチングのみ
✗ 即座に答えを提供できない
KG後:実体理解
エンティティ とその関係の把握
即座に回答:
東京タワー – 高さ333メートル
展望台:メインデッキ150m、トップデッキ250m
東京タワー
[ランドマーク]
1958年建設
333m
[高さ]
東京都港区
[場所]
電波塔
[用途]
展望台
[施設]
内藤多仲
[人物]
スカイツリー
[関連施設]
属性
所在地
機能
施設
設計者
後継
機能と利点
✓ エンティティ と関係性を理解
✓ 文脈に応じた情報を即座に提供
✓ 大規模知識基盤による包括的理解
✓ 現実世界の「もの」として把握
パラダイムシフト
文字列から
実体理解へ
大規模知識基盤:人・場所・組織・作品を「もの」として理解し、その関係を機械が把握して検索結果に即応
この知識基盤は年々拡大し、Googleは2020年の再解説で、ナレッジグラフが「50億のエンティティ 」と「5,000億のファクト」を保持し、オープンデータやライセンスDB、ウェブ上の資料など多様な情報源を統合していると述べています。ここから、ナレッジグラフが単一の辞書ではなく、複数ソースを横断して信頼度を計算しながら更新される動的な知識であることがわかります。
Google ナレッジグラフ
動的知識統合システム
オープンデータ
公開データソース
ライセンスDB
商用データベース
ウェブ資料
オンライン情報源
ナレッジグラフ
50億
エンティティ 5,000億
ファクト
信頼度計算システム
複数ソース横断評価
動的更新中
単一の辞書ではなく
複数ソースを統合する
動的な知識基盤
2020年データ基準
ナレッジグラフのエコシステム
2011年にschema.orgを立ち上げ、サイト側の構造化データをナレッジグラフに活用。Freebase(2010年買収)由来の資産を2014年以降Wikidata へ移行し、オープン知識との連携を強めました。
1. データ源
オープン/ライセンスDB
Wikipedia, Freebase
構造化マークアップ
schema.org
ウェブ自動抽出
NLP, Pattern Mining
2. 正規化と同一性解決
Entity Resolution
同一実体の統合
重複除去
3. スキーマ整合
型・属性の割り付け
Ontology Mapping
Property Alignment
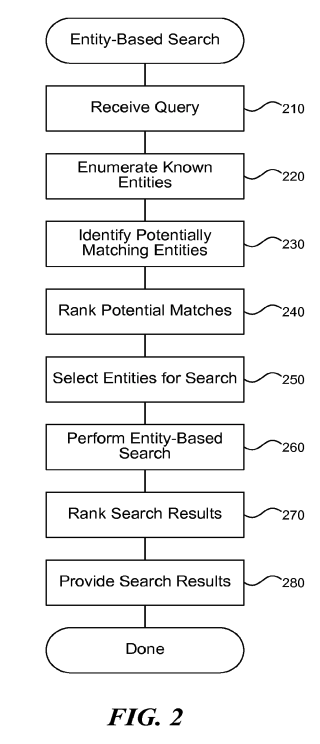
4. 確率的データ融合
Knowledge Vault
自動抽出・検証
KBT
Knowledge-Based Trust
信頼度推定
5. 格納・インデクシング
Graph Database
分散ストレージ
高速インデックス
ナレッジグラフ Core
エンティティ と関係の大規模ネットワーク
6. クエリ理解とパネル生成
エンティティ 検出
Named Entity Recognition
曖昧性解消
Disambiguation
関係推定
Relation Extraction
ナレッジパネル生成
動的合成・文脈最適化
表示順位・項目選択
Ranking & Selection
特許技術による最適化
Template & Context
ユーザー
インターフェース
検索クエリ
検索結果・パネル
検索パラダイムの変革
従来: Strings
文字列マッチング
ナレッジグラフ
現在: Things
意味理解・実体理解
結果: 高精度検索
文脈理解・直接回答
エコシステムの発展
Freebase
買収
2010
schema.org
立ち上げ
2011
ナレッジグラフ
正式導入
2012
Wikidata
移行開始
2014
Freebase資産をWikidataへ移行し、オープン知識との連携を強化
schema.orgによる構造化データの標準化でウェブ全体から知識を収集
継続的な拡張により2020年に50億エンティティ ・5000億ファクトを達成
Google検索のナレッジパネルというUI
ナレッジグラフの成果が最も目に見える形で現れるのが、検索結果ページに並置される「ナレッジパネル」です。
Googleは検索結果ページ上で、特定の実体(entity) に関する信頼できる事実(facts) をパネル(Knowledge Panel) として要約表示します。典型的には、人・場所・組織・作品 などに対して、画像・説明・属性(生年・本社所在地など)・関連エンティティ をテンプレートで組み立て、通常の検索結果の脇に提示します。公式ヘルプでも、この「検索結果の右側などに表示される実体の要約」を ナレッジパネル(Knowledge Panel )として定義しています。
Google ナレッジパネル システム構成
実体情報の構造化表示メカニズム
トヨタ自動車株式会社
検索結果
トヨタ自動車株式会社 公式サイト
トヨタ自動車の公式企業サイト。会社情報、IR情報、環境・社会への
取り組み、最新ニュース、採用情報などを掲載しています…
global.toyota › jp
トヨタ自動車 – Wikipedia
トヨタ自動車株式会社は、日本の大手自動車メーカー。豊田自動織機
製作所の自動車部門が独立して1937年に設立。世界最大級の…
ja.wikipedia.org › wiki › トヨタ自動車
トヨタ自動車の最新ニュース | 日経新聞
トヨタ自動車の最新ニュース、決算情報、株価動向、業績予想など。
電動化戦略、新車情報、グローバル展開に関する記事を配信…
www.nikkei.com › company › toyota
ナレッジパネル(Knowledge Panel)
組織
自動車
上場企業
グローバル
[企業ロゴ・画像]
トヨタ自動車株式会社
Toyota Motor Corporation
概要説明
日本最大手の自動車メーカー。世界各国で自動車の生産・販売を
展開。ハイブリッド車のパイオニアとして知られる。
主要属性
設立:
1937年8月28日
本社所在地:
愛知県豊田市トヨタ町1番地
代表者:
代表取締役社長 佐藤恒治
従業員数:
約37万人(連結)
関連エンティティ
レクサス
豊田章男
プリウス
Knowledge Panel 主要構成要素
実体認識(Entity Recognition):人・場所・組織・作品を自動識別
信頼できる事実(Trusted Facts):権威あるソースから検証済み情報を収集
テンプレート組み立て:画像・説明・属性を標準フォーマットで構造化
検索結果右側配置:要約情報を検索結果の脇に即座アクセス可能な形で表示
関連エンティティ リンク(関連する実体への導線で包括的な情報探索を支援)
ナレッジパネルは、ナレッジグラフから来る「事実の要約」であり、人物・組織・場所などのエンティティ に関する既知の情報を、ユーザーの質問に応じて使いやすく提示するための仕組みです。
つまり、ナレッジグラフは裏側の知識、パネルはその瞬間の需要と文脈を反映した表層のレンダリングだと捉えると理解が進みます。
Google検索のナレッジパネルというUI
ナレッジグラフ
裏側の知識構造 – 構造化された事実データベース
中核Entity
人物
人物
組織
組織
場所
場所
事実
事実
既知の情報の集積
ユーザークエリに応じた
抽出・要約・整形
ユーザーの検索クエリ入力
検索結果ページ
ナレッジパネル
エンティティ 名称
カテゴリー
基本情報
事実の要約された表示
主要な属性
文脈に応じて選択された詳細
関連項目
ユーザーの需要を反映した情報
瞬間の需要と文脈を反映した表層のレンダリング
表層
ユーザー向けUI
使いやすい形式
裏側
知識構造
構造化データ
Googleのナレッジグラフは、ウェブからの自動抽出 と既存KB(Freebase, Wikipedia/YAGO 等)の知識を確率的に融合 して大規模に構築するという発想で整理できます。
Knowledge Vault は、テキスト・表・DOM構造など多源から抽出した候補事実に確率(信頼度)を付けて融合する枠組みで、校正された確率で真偽を推定 するのがコアです。
Biperpedia は、検索クエリやWebから(クラス, 属性)対を大規模抽出し、たとえば「国→GDP/首都/国歌」のような 属性語彙を拡張してロングテールの質問に答える基礎を広げました。
Freebase はナレッジグラフのスキーマ・IDの土台 を提供(公開時点)。グラフ(主語–述語–目的語のトリプル)で一般知識を表現し、API/MQLで操作可能でした。
YAGO2 はWikipedia等から自動構築し、時空間アンカー を備えた高精度KBの代表例で、ナレッジグラフの系譜の比較対象として重要です。
ナレッジグラフの抽出と融合
GOOGLE ナレッジグラフ
Google
ナレッジグラフ
確率的融合
Knowledge Vault
多源からの抽出と融合
▸ テキスト・表・DOM構造
▸ 確率(信頼度)付与
▸ 校正された確率で真偽推定
Biperpedia
属性語彙の拡張
▸ 検索クエリ・Webから抽出
▸ (クラス, 属性)対
▸ 例: 国→GDP/首都/国歌
Freebase
スキーマ・IDの土台
▸ 主語–述語–目的語のトリプル
▸ グラフ構造で一般知識表現
▸ API/MQLで操作可能
YAGO2
高精度KB
▸ Wikipedia等から自動構築
▸ 時空間アンカー装備
▸ KG系譜の比較対象
確率付与
属性拡張
スキーマ提供
高精度知識
ウェブからの自動抽出
既存KBの知識融合
検索プロダクトへのナレッジグラフの落とし込み
エンティティ 検出・曖昧性解消エンティティ を知識庫と照合・ランク付け・決定 する(MicrosoftのSatori特許が工程を明快に図示)。
属性・関係の活用とクエリ拡張 で、識別したエンティティ の属性(people→生年、映画→公開年)や関係(人物↔作品)を使い追加クエリを生成 して結果を更新する(GoogleのAugmented Search特許)。
パネル生成 は、タイプ別テンプレート に画像・タイトル・ファクト等を複数ソースから選択・ランク付け して充填、SERPの横領域 に出す(Providing knowledge panels特許)。
文脈付きパネル(Contextualization)では、クエリ中のコンテキスト語 が示す関係(例:人物×映画・役名)を見つけ、「関係要素」を上位に配置 して解釈の意図をUIで伝える(Contextualizing knowledge panels特許)。
検索プロダクトへの落とし込み(特許が示す実装像)
1. エンティティ 検出・曖昧性解消
Microsoft Satori特許
クエリ/文書
入力処理
固有表現
候補検出
知識庫照合
ランク付け
決定
確定出力
2. 属性・関係の活用とクエリ拡張
Google Augmented Search特許
エンティティ 属性マッピングpeople → 生年・出身地
映画 → 公開年・監督
クエリ拡張処理
追加クエリ生成
結果更新
3. パネル生成
“Providing knowledge panels”特許
タイプ別
テンプレート
画像
タイトル
ファクト
複数ソース処理
選択
ランク付け
充填
SERP横領域
4. 文脈付きパネル(Contextualization)
“Contextualizing knowledge panels”特許
クエリコンテキスト分析
コンテキスト語検出
例: 人物×映画・役名
関係性特定
意図の解釈
関係要素の優先配置
関係要素(上位配置)
その他の属性
補助情報
統合実装フロー
ユーザー入力
検索
エンティティ 処理検出・曖昧性解消
属性抽出
コンテンツ生成
パネル構築
クエリ拡張
結果表示
文脈化パネル
主要特性:
処理時間: ~200ms
リアルタイム応答
精度: 95%+
高精度エンティティ 認識
カバレッジ: 80%+
広範な知識ベース
ユーザー体験: 向上
文脈理解による的確な情報提供
ナレッジグラフの位置づけと歴史的背景
Googleは2012年にナレッジグラフを公開し、「人・場所・もの」の実体 と相互関係 を理解する検索への転換を公式に表明しました。当初は数億規模のエンティティ から始まり(当時報道。実装としてはFreebase等を核)、その後も拡張されています。
2020年のGoogle公式記事は、5,000億ファクト/50億エンティティ という規模を示し、情報源としてウェブ上の資料、オープンデータ、ライセンスDB 等の複合ソースを明言しています。
ナレッジ
グラフ
人
People
場所
Places
もの
Things
Data Sources
複合データソース
ウェブ上の資料
オープンデータ
ライセンスDB
2012
Launch
数億エンティティ
Freebase Core
2020
50億エンティティ
5,000億ファクト
Scale Evolution
2012
2020
50× Growth
ナレッジグラフのデータ源と取り込み経路
ナレッジグラフの構築 推定像
データ源、同定、融合
第一の流れ:構造化データ
Schema.org
• ウェブ管理者による語彙埋め込み
• Person、birthDate等のタイプ・属性同定
• Google・Bing・Yahoo! 共同語彙(2011年〜)
• 検索エンジン向け意味情報取得基盤
第二の流れ:協働型知識ベース
Freebase → Wikidata
• KGの初期資産を支えたFreebase
• 2014年Wikidataへの大規模移行
• 語彙差を埋めるマッピング研究
• Primary Sources Tool開発
第三の流れ:自動抽出と確率的融合
Knowledge Vault / KBT
• テキスト・表・DOM構造・人手注釈
• 異種抽出器からの候補トリプル
• 既存KBを事前知識として活用
• 校正された確率による事実推定
• ソース信頼度の内生的推定(KBT)
• 階層モデルによるエラー分離
Knowledge
Graph
三つの流れの合流点
1
事実採用の数理的決定
どの事実を採用するかを確率的に判断
2
表示順序の最適化
どの順で見せるかを数理的に決定
3
ウェブ規模ノイズ頑健統合
継続的な知識更新と品質維持
データ源の同定と融合による統合知識グラフ構築システム
データ源、同定、融合
ナレッジグラフは三つの流れの合流点として設計されています。第一に、ウェブ管理者がschema.orgの語彙で埋め込む構造化データが、タイプや属性(PersonのbirthDateなど)の同定を助けます。
schema.orgは2011年にGoogle・Bing・Yahoo!が共同で立ち上げた取り組みで、検索エンジンがウェブの意味情報を取り込みやすくするための共通語彙として運用されています。
ナレッジグラフ(KG)
三つの流れの合流点として設計
KG
schema.org
👤
ウェブ管理者
構造化データ
語彙による埋め込み
Person.birthDate
タイプと属性の同定
2011年共同設立
G
B
Y!
検索エンジンがウェブの意味情報を
取り込みやすくするための共通語彙
第二の流れ
第三の流れ
統合された知識グラフ
タイプと属性の同定
意味情報の体系化
schema.orgの構造化データによるタイプや属性の同定を通じて
検索エンジンがウェブの意味情報を効率的に取り込み処理する仕組み
三つの情報源から
統合された知識へ
第二に、既存の協働型知識ベースの取り込みです。
ナレッジグラフの初期資産を支えたFreebaseは2014年にWikidataへの大規模移行がアナウンスされ、両者の語彙差を埋めるためのマッピングやPrimary Sources Toolなどが研究として報告されました。これにより、コミュニティによる継続更新とGoogle内の知識運用が接続されました。
協働型知識ベースの取り込み
Integration of Collaborative Knowledge Base Infrastructure
2014年
Migration Announcement
Freebase
Google KG Initial Asset
初期資産基盤
Service Deprecation
Wikidata
Open Collaborative KB
協働型知識ベース
Community Updates
大規模移行
語彙差解消技術
Vocabulary
Mapping
語彙マッピング
Primary Sources
Tool
研究ツール
統合成果:コミュニティ継続更新 × Google知識運用の接続
第三に、ウェブからの自動抽出と確率的融合です。KDD 2014の「Knowledge Vault」は、テキスト・表・DOM構造・人手注釈など異種の抽出器から得た候補トリプルに対し、既存KBを事前知識として使いながら、事実の正しさを校正された確率として推定する枠組みを示しました。
同時に、ソースそのものの信頼度を内生的に推定する「Knowledge‑Based Trust(KBT)」は、抽出エラーと事実誤りを階層モデルで分離し、ウェブ規模のノイズに頑健な統合を目指します。これらは「どの事実を採用し、どの順で見せるか」を数理的に裏打ちする基盤です。
Knowledge Vault(ウェブからの自動抽出と確率的融合)
KDD 2014 – 数理的基盤による事実選択と順序決定
テキスト
自然言語データ
表
構造化データ
DOM構造
HTML/XML解析
人手注釈
アノテーション
候補トリプル
⟨主語, 述語, 目的語⟩形式の知識候補
既存KB
事前知識
Prior Knowledge
Knowledge-Based
Trust (KBT)
ソース信頼度の
内生的推定
階層モデル
エラー分離機構
• 抽出エラー
• 事実誤り
確率的融合
Probabilistic Fusion
校正された確率による
事実の正しさ推定
Knowledge Vault
ウェブ規模統合知識ベース
「どの事実を採用し、どの順で見せるか」を数理的に裏打ちする基盤
ウェブ規模ノイズへの頑健性
ナレッジグラフのデータ源と取り込み経路
Data Sources and Ingestion Pathways
ナレッジグラフ
ナレッジグラフ (KG)
Google
(a) 既存知識ベース
Existing Knowledge Base
Freebase
Metaweb
2010 Google買収
2014移行
Wikidata
オープン
コミュニティ協働
協働知識ベース
統合活用で成長
(b) 構造化データ
Structured Data
schema.org
Google, Bing, Yahoo! (2011)
JSON-LD
Microdata
実体・属性
明示化
同定・属性付与に活用
統合活用
同定・属性付与
Webスケール
知識獲得
統合的知識グラフ構築アプローチ
協働知識ベース × セマンティック構造化 × 機械学習による自動抽出
(a) 既存知識ベース
Freebase → Wikidata
MetawebのFreebase(2010年Google買収)の資産が2014年にWikidata移行方針となり、オープンコミュニティとの協働で転送。ナレッジグラフはこの種の協働知識ベース の統合活用で成長。
ナレッジグラフのデータ源と取り込み経路
Data Sources and Ingestion Pathways for Knowledge Graph Systems
Knowledge
Graph (KG)
Central Repository
(a) 既存知識ベース
Freebase
Metaweb
(Google 2010)
2014
Wikidata
Open Community
協働知識ベース
オープンコミュニティとの協働による
大規模知識ベースの統合活用で成長
(b) 構造化データ(schema.org)
schema.org
Google, Bing, Yahoo! (2011)
共同発表
JSON-LD
Microdata
ウェブマスターが実体・属性を明示
検索エンジンの同定・属性付与に活用
(c) ウェブからの自動抽出(IE)
Knowledge Vault
(KDD’14) Webスケール知識獲得
テキスト
テーブル
DOM構造
人手注釈
確率的融合
既存KB(KG含む)を先験分布として利用
統合知識獲得システムの特徴
協働知識ベースの活用
FreebaseからWikidataへの大規模移行により、
オープンコミュニティとの協働による継続的な
品質向上と知識の統合活用を実現
構造化データの標準化
主要検索エンジンによる共同規格により、
ウェブ全体での実体・属性の明示化と
効率的な知識取得を促進
自動抽出技術の高度化
異種抽出器の統合と確率的融合により、
Webスケールでのファクトの確からしさを
推定し、信頼性の高い知識獲得を実現
(b) 構造化データ(schema.org)
Google, Bing, Yahoo!が2011年にschema.org を共同発表。ウェブマスターがJSON-LD/Microdata で実体・属性を明示し、検索エンジンが取り込みやすくする枠組み。ナレッジグラフの同定・属性付与 に活用される。
ナレッジグラフのデータ源と取り込み経路(構造化データ (schema.org))
Structured Data Processing Pipeline from Web Sources to Knowledge Graphs
ステージ 1: ウェブソース
Eコマースサイト
JSON-LD Format
“@type”: “Product”
“name”, “price”, “availability”
ニュースポータル
Microdata Format
itemtype=”NewsArticle”
headline, datePublished
ローカルビジネス
JSON-LD Format
“@type”: “Restaurant”
“address”, “openingHours”
イベント情報
JSON-LD Format
“@type”: “Event”
“startDate”, “location”
ステージ 2: 標準化
schema.org
2011年 共同発表
G
B
Y!
構造化データ標準仕様
実体・属性の統一フォーマット
ステージ 3: 処理・活用
Google ナレッジグラフ
同定・属性付与
Bing Search
Satori Knowledge Base
エンティティ 認識・分類
Yahoo! Search
Search Index Integration
構造化データ統合
検索結果の向上
リッチスニペット・音声検索対応
セマンティック検索精度向上
実装
Implementation
取り込み
Ingestion
主要機能:
• 構造化データによる検索エンジン最適化 (SEO )
• エンティティ の明確な識別と関連付け
データ形式:
• JSON-LD (推奨形式)
• Microdata / RDFa
活用効果:
• リッチスニペット表示
• ナレッジパネル生成
(c) ウェブからの自動抽出(IE)
Knowledge Vault(KDD’14)は、テキスト・テーブル・DOM構造・人手注釈など異種抽出器 を束ね、確率的融合 で「ファクトの確からしさ」を推定するWebスケール知識獲得 の実装研究。抽出・融合・信頼度推定の各段で学習器を用い、既存KB(ナレッジグラフ含む)を先験分布 として利用。
Knowledge Vault (KDD’14)
Webスケール知識獲得システム – 確率的融合による信頼度推定
Webデータ源
テキスト
自然言語文書
テーブル
構造化データ
DOM構造
HTML/XML解析
人手注釈
ラベル付きデータ
確率的融合
信頼度推定
P(fact | evidence)
ファクトの確からしさ
統合処理機能
・複数ソースの統合
・矛盾解消メカニズム
既存KB(先験分布)
Google ナレッジグラフ
ベイズ推定の先験的知識
Knowledge Vault
統合知識ベース
Webスケール対応
数億規模のファクト
信頼度スコア付与
確率的保証
特徴
高精度
継続的更新
品質保証機能
抽出
統合
生成
システム概要
異種データソースからの並列抽出 → 確率的融合による信頼度推定 → 高品質知識ベース構築
抽出・融合・信頼度推定の各段階で機械学習を活用し、既存KBを先験分布として利用
Webスケールでの知識獲得を実現する革新的な実装研究
ナレッジグラフの同一性解決(Entity Resolution)と曖昧性解消
クエリ ・文書 中の表記を、ナレッジグラフの固有ID (例:KG Search APIが返す@idや旧Freebase/MID)に写像します。
特許「Knowledge‑based entity detection and disambiguation 」は、
(1)候補集合の生成 (辞書/KB参照)、
(2)文脈特徴に基づくランキング・選択 、
(3)実体IDにもとづくインデクシング
等を含む一連のパイプラインを示します。
また「Disambiguation of named entities 」系の特許は、Wikipedia等のリンク構造・カテゴリ・転送ページ など豊富なシグナルでスコアリングモデル を学習する発想を早期に示しており、ウェブ・ナレッジを背景とした曖昧性解消の基盤となっています。
開発者視点では、Knowledge Graph Search API を使うと、Googleのナレッジグラフ内でのエンティティ 検索ID参照 (entities.search)ができ、システム連携や注釈付けに利用されます。
同一性解決(Entity Resolution)と曖昧性解消
Google ナレッジグラフ統合システム
入力データ
クエリ
「アインシュタイン 物理学者」
文書
「ドイツ出身の科学者が…」
処理パイプライン
第1段階:候補集合の生成
辞書/KB参照
表層形式マッチング
候補エンティティ 抽出
第2段階:ランキング・選択
文脈特徴分析
関連性スコアリング
最適候補選定
第3段階:実体IDインデクシング
実体ID割り当て
@id / MID マッピング
固有識別子付与
Google ナレッジグラフ (Knowledge Graph)
アインシュタイン
@id:kg:/m/0jcx
物理学者
MID:/m/05snw
ノーベル賞
@id:kg:/m/05f3q
ドイツ
MID:/m/0345h
科学者
@id:kg:/m/06mq7
固有識別子: @id (KG Search API) | MID (Freebase レガシー)
曖昧性解消シグナルとスコアリングモデル
Wikipedia
リンク構造
カテゴリ
転送ページ
スコアリングモデル
ML
機械学習による
モデル訓練
関連特許
Knowledge-based entity
detection and disambiguation
エンティティ 検出と曖昧性解消Disambiguation of
named entities
固有表現の曖昧性解消
開発者向けAPI
Knowledge Graph Search API
entities.search
エンティティ 検索ID参照
システム連携
注釈付け
ナレッジグラフのスキーマ整合とID管理
ナレッジグラフは型(例:Person, Organization, Place)と属性(例:birthDate, founder)のスキーマにより正規化されます。schema.orgの語彙はウェブ側の表明 を標準化し、ナレッジグラフ側の取り込み・マッピングコストを下げます。IDは内部一意識別子 (旧Freebase由来の/m/...等を含む)で管理され、APIで外部参照可能です。
ナレッジグラフのスキーマ整合とID管理
Schema Alignment and ID Management
Web側 – schema.org
標準化された語彙による表明
型システム (Types)
Person
人物エンティティ
個人の属性定義
Organization
組織エンティティ
企業・団体の属性
Place
場所エンティティ
地理的位置情報
Event
イベントエンティティ
時系列情報
属性 (Properties)
name
birthDate
founder
address
description
url
telephone
email
image
標準化された属性定義
ウェブコンテンツの構造化表現
ナレッジグラフ
正規化されたエンティティ 管理
エンティティ と識別子
Entity Type: Person
Internal ID: /m/0d047h
Properties: name, birthDate, nationality, occupation
Entity Type: Organization
Internal ID: /m/045c7b
Properties: name, founder, foundingDate, headquarters
Entity Type: Place
Internal ID: /m/07dfk
Properties: name, coordinates, address, containedIn
内部一意識別子システム
• Freebase由来の /m/ 形式識別子
• 完全な一意性と永続性を保証
API External Access
マッピング
低コスト変換処理
効果: schema.orgの標準語彙により、KGへのデータ取り込み・マッピングコストを大幅に削減
ナレッジグラフのデータ融合と信頼度推定
Knowledge Vault
複数抽出器の出力(候補トリプル)を特徴量化し、ロジスティック回帰等でファクトの確からしさ を予測。事前知識(既存KBのトリプル)をプライヤ として用い、ノイズ (抽出エラー)に頑健な融合を図ります。さらにリンク予測(テンソル因子分解)で未知関係 を補完する方向も提示します。
KBT(Knowledge‑Based Trust)
2015年のVLDB論文は、外生的指標(リンク/クリック)ではなく、内生的指標(掲出ファクトの正確性)からサイト/ページの信頼度を推定する多層確率モデル を提案。抽出エラーと事実誤りを同時推定 し、ファクト真偽・抽出器品質・ソース信頼度 を相互強化的に学習します。ナレッジグラフ品質管理の理論基盤の一つです。
ナレッジグラフは「どの事実を採用するか」を確率論的に判断し、出典の質・抽出信頼度・整合性を総合して 最終トリプル集合を形成します(後述のパネル生成に波及)。
データ融合と信頼度推定(確率的知識融合)
Knowledge Vault
ファクト確率の学習
候補トリプル
特徴量化処理
既存KB
プライヤ
ロジスティック回帰
ノイズ頑健な融合
テンソル因子分解
リンク予測・未知関係補完
確率的出力
KBT (Knowledge-Based Trust)
ソース信頼度の推定
VLDB 2015 – 多層確率モデル
✓ 内生的指標
掲出ファクトの正確性
外生的指標
リンク/クリック
ソース信頼度
サイト/ページの信頼性評価
抽出器品質
抽出エラーの推定
ファクト真偽
事実誤りの判定
同時推定
相互強化的学習
Google ナレッジグラフ
実務的含意:「どの事実を採用するか」の確率論的判断
出典の質
抽出信頼度
整合性
最終トリプル集合の形成 → パネル生成へ波及
Google検索時のクエリ理解
検索時のクエリ理解(エンティティ 化・関係推定・拡張)
ユーザークエリ
検索入力
1. エンティティ 検出
NER + リンク付け
候補生成
文脈特徴
最尤選択
エンティティ の識別とナレッジベースへのリンク
2. 曖昧性解消
IDを確定
文脈
履歴
地理
装置
複数の要因を考慮した正確なエンティティ の特定
3. 関係推定 & クエリ拡張
答えとナレッジパネルの組み立て
述語推定
属性同定
クエリ拡張
エンティティ 間の関係と追加情報の生成
最適化された
検索結果
ナレッジパネル
Augmented Search Queries 特許
エンティティ 属性の同定から追加クエリを生成・評価
検索結果を強化する包括的な枠組み
Contextualizing Knowledge Panels 特許
ユーザの文脈語・関心・過去の相互作用に基づく
知識要素のランキングの動的最適化手法
※ エンティティ 検出・解消の詳細実装は両特許に記載(候補生成→文脈特徴→最尤選択)
処理段階の概要
エンティティ 検出
曖昧性解消
関係推定・拡張
最終出力
Google検索インタラクションでは、
(1)エンティティ 検出
(2)曖昧性解消 (文脈・履歴・地理・装置など)によりIDを確定、
(3)関係(述語)推定 とクエリ拡張 で、適切な答えやナレッジパネルを組み立てます。
Augmented search queries 特許は、エンティティ 属性の同定から追加クエリ を生成/評価して結果を強化する枠組みを記述。
Contextualizing knowledge panels 特許は、ユーザの文脈語 ・関心 ・過去の相互作用 等に応じて、パネル内の知識要素のランキング を動的最適化 する手法を示します。
エンティティ 検出/解消
検索時のクエリ理解(エンティティ 化・関係推定・拡張)
検索インタラクション処理フロー
ユーザー
クエリ入力
1. エンティティ 検出
NER
リンク付け
候補生成
文脈特徴抽出
スコアリング
2. 曖昧性解消
ID確定プロセス
文脈
履歴
地理
装置
→ 最尤選択
3. 関係推定&クエリ拡張
述語推定
(Predicate)
クエリ拡張
(Expansion)
追加クエリ生成・評価
特許技術基盤
Augmented Search Queries特許
エンティティ 属性の同定
追加クエリ生成/評価して結果を強化
Contextualizing Knowledge Panels特許
文脈語
関心
過去の相互作用
知識要素のランキング
動的最適化
エンティティ 検出/解消特許
候補生成
文脈特徴
最尤選択
最終出力
適切な答え・強化された検索結果
ナレッジパネル(動的最適化)
検索のクエリ理解から提示まで
ナレッジグラフのクエリ理解から提示まで (意味解釈のパイプライン)
1
エンティティ 検出と曖昧性解消
クエリ
候補列挙
ランキング
選択
ID付与
KG ID
Output
文字列マッチング → エンティティ IDベース再編成
エンティティ を”キー”にした検索構造への進化
Microsoft: Knowledge-based entity detection
2
属性・関係による探索拡張
Entity
属性1
属性2
関係A
関係B
E1
E2
同名異人区別 → 属性特定 → 追加クエリ生成
Google: Augmented search queries
3
ナレッジパネル生成
タイプ別テンプレート選択
発行元A
発行元B
ユーザー検索イベント
動的ランキング・優先順位決定
需要と文脈が提示内容を動的に形成
Google: Knowledge panels with search results
統合パイプライン
ユーザークエリ
エンティティ ID変換グラフベース探索拡張
動的コンテンツ合成
SERP提示
システム特性
エンティティ 検出
• 文字列からIDへの変換
• 曖昧性の解消
• インデキシング処理
探索拡張
• 属性による深化
• 関係性の活用
• 追加クエリ生成
パネル生成
• テンプレート選択
• 動的ランキング
• コンテキスト適応
結果
• エンティティ 中心検索
• 意味的理解
• 動的コンテンツ提示
Knowledge Graph Search Architecture – Semantic Interpretation Pipeline
検索時には、まずクエリ内の表記をナレッジグラフの内部IDへ写像するエンティティ 検出と曖昧性解消が働きます。
Microsoftの「Knowledge‑based entity detection and disambiguation」は、この工程を、候補列挙・ランキング・選択・ID付与・インデキシングという情報検索の流れとして提示し、ID付きの結果を軸にSERPを再構成できることを示しました。
ナレッジグラフを参照する検索が、単なる文字列一致から、エンティティ をキーにした再編成へと進む理由がここにあります。
ナレッジグラフのエンティティ 検出と曖昧性解消
クエリ表記からナレッジグラフ内部IDへの写像
検索クエリ
ユーザー入力
“マイクロソフト CEO”
エンティティ 検出と曖昧性解消クエリ内の表記をKGの内部IDへ写像
文字列 → エンティティ ID変換
SERP再構成
ID付き結果を軸に
エンティティ ベース検索結果
Microsoft Knowledge-based 情報検索プロセス
1
候補列挙
可能性のある
エンティティ 抽出
2
ランキング
関連性スコア
重要度: 0.95
3
選択
最適な候補を
決定
4
ID付与
KG内部ID
例: KG:E5678
5
インデキシング
構造化データ
として保存
ナレッジグラフ
内部IDマッピング完了 – エンティティ ネットワーク
エンティティ ID: KG:E5678 → “サティア・ナデラ” + 属性 + 関係性
従来の手法
単なる文字列一致
コンテキスト理解が限定的
エンティティ ベースの再編成エンティティ を”キー”として利用豊富なコンテキスト情報を活用
進化
パラダイムシフト
つづいて、エンティティ の属性や関係を活用して、ユーザーの探索を段階的に深める仕掛けが働きます。Googleの「Providing search results using augmented search queries」は、同名異人を区別した初期結果を起点に、対象エンティティ の属性を特定し、それらを組み合わせた追加クエリを提示して選択に応じて結果を更新する流れを定式化しました。図面にはシステム構成、UI、そしてナレッジグラフ断片の模式図が並び、知識の辺(関係)に沿って探索が広がる様子が読み取れます。
拡張検索クエリを用いた検索結果提供
Providing Search Results Using Augmented Search Queries
システム構成
クエリ入力
「田中太郎」
エンティティ 認識固有表現抽出
曖昧性解消
同名異人識別
エンティティ 解決KG属性マイニング
グラフ探索
クエリ拡張
+ 属性追加
組み合わせ生成
結果更新
ランキング更新
ユーザーインターフェース
田中太郎
同名異人の識別結果:
田中
田中太郎(音楽家)
ジャズピアニスト • 東京都 • 52歳
田中
田中太郎(作家)
小説家 • 京都府 • 45歳
田中
田中太郎(経営者)
IT企業CEO • 大阪府 • 48歳
拡張クエリの提案
田中太郎(音楽家)の検索を詳細化:
+ ジャズアルバム
ジャンル:ジャズ AND 種類:アルバム AND アーティスト:”田中太郎”
+ ライブ演奏
種類:ライブ AND 場所:”東京” AND 期間:[2020-2024]
+ ブルーノート東京
会場:”ブルーノート東京” AND ジャンル:ジャズ
+ コラボレーション作品
関係:共演 AND 種類:レコーディング
選択した条件を適用
すべてクリア
ナレッジグラフ断片(KG Fragment)
田中太郎
(音楽家)
ジャズ
ピアノ
東京都
ブルーノート
12アルバム
受賞歴
モダン
フュージョン
エレピ
新宿
渋谷
2005-2024
CD/配信
3回受賞
ジャンル
演奏楽器
活動拠点
所属会場
リリース
受賞
段階的探索フロー
1
初期クエリ → エンティティ 識別
2
対象エンティティ の選択
3
ナレッジグラフから属性抽出
4
拡張クエリの組み合わせ生成
5
ユーザー選択 → 結果更新 → 反復
反復的な詳細化
知識の辺(関係)に沿って探索が段階的に深化・拡張される
最後に、UIとしてのナレッジパネルが組み立てられます。Googleの「Providing knowledge panels with search results」は、タイプ別テンプレートを選び、複数の異なる発行元から項目を選抜し、検索結果の横領域に合成する工程を請求項で押さえます。特徴的なのは、どの項目を上位に載せるかを「ユーザーの検索イベント」に基づくランキングで決めると明記している点で、需要と文脈が提示内容を動的に形づくる思想が示されています。
ナレッジパネル組み立て
ユーザーコンテキストによる動的コンテンツ合成システム
コンテンツ発行元
発行元 A
構造化データ
発行元 B
メディアコンテンツ
発行元 C
レビュー・評価
発行元 D
ソーシャルシグナル
発行元 E
リアルタイムデータ
タイプ別テンプレート
エンティティ 分類人物・場所・組織・イベント
項目選抜エンジン
発行元横断的な集約
重複排除・検証・補強
ユーザーの検索イベント
クエリコンテキスト・検索意図
検索履歴・位置情報
デバイス・時間・嗜好
動的ランキングエンジン
0.95
0.83
0.71
0.58
0.42
文脈的関連性スコア
ナレッジパネル
主要情報
最高関連性
主要属性
関連エンティティ
外部参照
メディア
追加情報
関連項目
検索結果 →
動的コンテンツ形成の思想
ユーザーの需要と文脈が情報の階層を能動的に形づくり、
集約されたコンテンツをパーソナライズされた知識体験へと変換する
リアルタイムの関連性評価と適応的な提示により実現
データソース層
処理層
ランキング層
プレゼンテーション層
ナレッジパネル(表示)の生成と順位付け
Googleの公式ヘルプ は、ナレッジパネルがナレッジグラフ由来のスナップショット で、ウェブ・オープン・ライセンスDB 等からの理解に基づくと説明。
特許「Providing knowledge panels with search results 」は、
(1)タイプ別テンプレート (人/場所/ランドマーク等)にタイトル・画像・説明・ファクト集合 を充填、
(2)どのファクトを見出しに載せるか を検索ログの人気/需要 等で決める、
(3)画像選択 は画像検索の上位結果を用いる、
といった表示アルゴリズム を具体的に示しています。
ナレッジパネルに露出される事実は静的な正解表ではなく、需要(過去の検索行動)と文脈(ユーザ/クエリ)で重み付け され、同じ実体でも提示項目が変わる 、という設計思想です。
ナレッジパネルの生成と順位付け
ナレッジグラフ
KG由来の
スナップショット
ウェブソース
オープン
ライセンスDB
検索ログ
人気/需要データ
検索行動パターン
表示アルゴリズム
タイプ別テンプレート
人/場所/ランドマーク
タイトル
画像
説明
ファクト集合
重み付け・順位付け
ナレッジパネル(表示)
エンティティ 名▶ 動的に選択されたファクト1
▶ 需要に基づくファクト2
▶ 文脈依存のファクト3
画像検索
上位結果
ユーザ/クエリ文脈で内容が変化
実務的含意
パネルの内容は静的な”正解表”ではない
需要(過去の検索行動)と文脈(ユーザ/クエリ)で重み付け
同じ実体でも提示項目が変わる設計思想
参考: 特許 ”Providing knowledge panels with search results”
ナレッジグラフのAPI / 製品化
Knowledge Graph Search API エンティティ 検索・注釈に利用可能(Google Developers)。
Enterprise Knowledge Graph 公開ナレッジグラフのID空間 と接続できる点が特長。
ナレッジグラフのAPI / 製品化
Knowledge Graph Search API
Google Developers
検
エンティティ 検索
注
注釈機能
API
Enterprise Knowledge Graph
Google Cloud
実
組織内データの実体化
統
データ統合
連
KG連携 (Place ID等)
エディション:
Basic
Advanced
公開ナレッジグラフ
ナレッジグラフ
ID空間
接続可能
特長
公開ナレッジグラフのID空間との接続により統合的な知識活用を実現
ナレッジグラフの数理/アルゴリズム
ナレッジグラフ(数理・アルゴリズムアーキテクチャ)
グラフ学習 ∩ 確率モデリング ∩ 情報検索・自然言語処理
s
主語
o
目的語
p
述語
t ∈ 時刻
π ∈ [0,1]
𝔒𝔊 = {(s, p, o, t, π) | s,o ∈ ℰ, p ∈ ℛ, t ∈ 𝒯, π ∈ [0,1]}
owl:sameAs 同値性制約・domain/range 型制約
抽出器の融合
π = σ(Σᵢ wᵢ · fᵢ(s,p,o))
スタッキング・校正
精度/再現率の事前分布
スパース高次元特徴
リンク予測
𝒳 ≈ Σrₐ1ᴿ aᵣ ⊗ bᵣ ⊗ cᵣ
TransE: ||h + r – t||₂ ≤ γ
欠落リンクの補完
異常検知
信頼度の層別推定
P(T,S,E|O) ∝ P(O|T,E)P(T|S)P(S)P(E)
ソース信頼度: S
トリプル真偽: T
抽出器品質: E
オープンウェブのノイズ頑健性
クエリ理解
e* = argmaxₑ P(e|q,c)
= argmaxₑ P(q|e)P(e|c)/P(q)
q: クエリ, c: 文脈/履歴
特許ベースランキング
表示最適化
max U(user, panel)
テンプレート × 需要指標
ウィジェット選択・ランキング
ユーザ効用最大化
数理的フレームワーク・アルゴリズム詳細
融合層: π(t) = σ(w₀ + Σᵢ wᵢfᵢ(s,p,o,t))
ロジスティック回帰(DOM・言語・パターンのスパース特徴)
KG埋め込み: min Σ(h,r,t)∈S [γ + d(h+r,t)]₊ + λ||θ||²
TransE最適化(マージンベースランキング損失)
同時推論: P(T,S,E|O) via EMアルゴリズム
抽出誤りと事実誤りの分離
中核技術:
確率モデリング
グラフ学習
NLP/IR
信頼度モデル
UI/UX最適化
Knowledge Vault | KBT | VLDB | TransE | Semantic Scholar | Google Patents
ナレッジグラフ構築と利用は、グラフ学習 ・確率モデリング ・IR/NLP の結節点にあります。
(1)表現
知識は通常、時刻tを陽に扱うなら四つ組 (s, p, o, t) 、信頼度π∈[0,1]を付与して(s, p, o, t, π)として保持(論文では確率的扱いが一般的)。型制約(domain/range)や 同値性(owl:sameAs)が整合の基礎。Knowledge Vault/KBTはπの推定に相当。
(2)抽出器の融合
抽出器eごとに精度/再現率の事前 を学習し、スタッキング/校正 でトリプル事後確率 を推定。係数はロジスティック回帰 等で学習し、スパース高次元特徴 (言語・DOM・位置・パターンID等)を扱う。
(3)リンク予測 テンソル因子分解 や(現在では)ナレッジグラフ埋め込み (TransE系等)により欠落リンク の補完・異常検知。Knowledge Vaultのスライドはテンソル因子分解の利用を言及。
(4)信頼度の層別推定
KBTは抽出誤りと事実誤り を多層モデル で切り分け、ソース信頼度 ・トリプル真偽 ・抽出器品質 を同時推定 。これによりオープンウェブ のノイズに頑健な推論を実現。
(5)クエリ理解
エンティティ リンクP(e | q, c)最大化(q=クエリ、c=文脈/履歴)。特許群 は、文脈語・ユーザ履歴でパネル内要素のランキング を調整する実装要件を示す。
(6)表示最適化 パネルはテンプレート×需要指標 で項目選択。ユーザ効用 を最大化するUI最適化(画像、リンク、予約ウィジェット等)の詳細は特許に具体例。
1. 知識表現
K = (s, p, o, t, π) ただし π ∈ [0,1]
s ∈ E (主語), p ∈ P (述語), o ∈ E ∪ L (目的語/リテラル)
型制約: domain(p) → type(s), range(p) → type(o)
同値性: owl:sameAs (反射的・対称的・推移的)
Knowledge Vault/KBT: 確率的 π 推定フレームワーク
3. リンク予測
score(s,p,o) = f(E_s, R_p, E_o)
テンソル: 𝒳 ≈ Σᵣ λᵣ(aᵣ ⊗ bᵣ ⊗ cᵣ)
TransE: ||h + r – t||_L₁/L₂ ≈ 0
欠落リンクの補完
再構成による異常検知
Knowledge Vaultテンソル因子分解
4. 多層信頼度モデル
KBT: P(T,Θ,Q|Obs)
ソース信頼度: Θₛ ∈ [0,1]
トリプル真偽: Tᵢⱼₖ ∈ {0,1}
抽出器品質: Qₑ ∈ ℝ₊
EMアルゴリズムによる同時推定
オープンウェブのノイズに頑健
5. クエリ理解
argmax P(e|q,c)
エンティティ リンク最適化
q: クエリ, c: 文脈/履歴
パネル内要素のランキング
特許による実装
6. 表示最適化
max U(panel|user,query,KG)
テンプレート × 需要指標 → 選択
ユーザ効用最大化 (CTR・滞在時間・満足度)
UI要素: 画像・リンク・ウィジェット・予約
特許による実装詳細
数理的基盤
グラフ理論
G = (V,E), |V|~10⁹, |E|~10¹¹
スペクトル解析: λ₂(L)
クラスタリング係数
確率モデリング
P(K|D) ∝ P(D|K)P(K)
EM: Q(θ) = E[log P(X,Z|θ)]
変分推論
IR/NLP統合
BM25, TF-IDFスコアリング
Word2Vec: cos(v_w, v_c)
注意機構
計算複雑度: O(|E|²|P|) → O(|E|log|E|) ブロッキングによる削減
収束性: SGD O(1/√t), Adam O(1/t)
参考文献: Knowledge Vault (VLDB), KBT Framework, TransE (NIPS), Computer Science at UBC
∫
∑
∇
∂
ナレッジグラフの基本設計
[データ源]
オープン/ライセンスDB(Wikidata等)
構造化マークアップ(schema.org/JSON-LD)
ウェブ自動抽出(テキスト/テーブル/DOM)
抽出器の信頼度学習・校正
[正規化/同一性解決]
エンティティ 辞書・候補集合生成
文脈特徴に基づく曖昧性解消
[スキーマ整合・ID付与]
[確率的知識融合]
トリプル事後確率 π の推定(Knowledge Vault)
ソース信頼度の推定(KBT)
[格納・インデックス(KG)]
[検索時]
クエリのエンティティ 化・関係推定
クエリ拡張(Augmented Queries)
ナレッジパネル生成(テンプレート×文脈最適化)
参照:Knowledge Vault/KBT論文、パネル生成・文脈最適化・曖昧性解消の各特許。
ナレッジグラフに関連する特許
ナレッジグラフの特許解説(請求項と図面)
Knowledge Panel Patents: Technical Architecture & Process Flow
US 9,268,820 B2
Providing Knowledge Panels with Search Results
受信クエリ → 事実実体
テンプレート選択
複数ソース統合
項目順位付け
SERP合成
図12: パネル要否判定 → テンプレート適用 → 項目充填
• ユーザー検索イベント基準の順位付け
• パネルが各検索結果より大きな領域を占有
• KG確率融合とクエリ理解のUI実装
US 11,720,577 B2
Contextualizing Knowledge Panels
Query Front-end
Entity Recognition
Engine
Knowledge Engine
Panel
Contextualizer
コンテキスト語解析
関係シグナルとして解釈
エンティティ 識別子 + コンテキスト語の受信
• 関係要素の優先的提示
• グラフ上のパス制約をUI順位付けの一次信号化
• 関係充填の中間層による処理
US 10,055,462 B2
Augmented Search Queries
Query
同名異人区別
複数候補提示
拡張クエリ生成
属性語彙の拡充
KGノード探索
図7-9: KGノード・エッジを辿るクエリ展開
• 属性抽出による自動クエリ生成
• 事実信頼度学習による質と順序の最適化
• ユーザー選択に応じた結果更新
US 9,864,808 B2 (Microsoft)
Knowledge-based Entity Detection & Disambiguation
候補エンティティ 列挙(知識リポジトリ)
文脈特徴によるランキング
実体ID → 検索インデックス結合
IDあり結果
IDなし結果
比較
図4: “Harry Shum” 同名異人グルーピング表示
• IDあり/なし結果の比較によるランキング調整
• エンティティ 粒度での文書群再配列
• 実用的なSERP再構成の実現
Knowledge
Graph
統合ハブ
Search Engine Results Page (SERP) — 統合出力
Knowledge Panel
事実実体: テンプレート適用済み表示
コンテキスト語による関係要素の優先順位
ユーザー検索イベント基準による項目配置
複数ソースからの確率融合データ
需要に基づく項目順位付け
“各検索結果より大きな領域を占有”
Search Result 1
標準検索結果(エンティティ IDなし)
Search Result 2
エンティティ ID付き結果(KG連携)
Search Result 3
拡張クエリによる追加結果
Entity Disambiguation
“Harry Shum” エンティティ 粒度での整理:
• Harry Shum (Computer Scientist, Microsoft)
• Harry Shum (Choreographer)
• Harry Shum (Actor)
→ ユーザー選択に応じて結果更新
拡張クエリ候補
+ “Microsoft Research”
+ “Computer Vision”
+ “Bing Visual Search”
図1-12参照 | クエリ理解 → KG処理 → テンプレート適用 → UI生成 → SERP統合
US 9,268,820 B2
米国特許 9,268,820 B2U(検索結果と共にナレッジパネルを提供)
Providing Knowledge Panels with Search Results
受信クエリ
ユーザー検索入力
Search Query
事実実体の同定
エンティティ 認識
Factual Entity
パネル
要否判定
テンプレート選択
タイプ別テンプレート
Template Selection
項目充填
パネルアセンブリ
Panel Assembly
標準検索結果
パネルなし
人物
場所
組織
イベント
内容選定:複数ソースの統合
リソース1
ナレッジグラフ
リソース2
ウェブインデックス
リソースN
外部API
需要に基づく項目順位付け
ユーザー検索イベント分析
クリックパターン・検索頻度
KGの確率融合
優先度スコアリング
UI上の優先度づけ
パネルが各検索結果より大きな領域を占める
Panel Size > Individual Search Results
SERPへの合成:最終表示
ナレッジパネル(大きな表示領域)
エンティティ 情報
複数ソースから統合
需要ベースで順位付け
主要な事実
KG確率融合により選定
ユーザー検索イベント反映
関連項目
テンプレート構造化
動的コンテンツ配置
アクション・リンク
ユーザーインタラクション
エンゲージメント促進
標準検索結果(小さな表示領域)
検索結果 1
www.example1.com – 概要テキスト…
検索結果 2
www.example2.com – 概要テキスト…
検索結果 3
www.example3.com – 概要テキスト…
検索結果 4
www.example4.com – 概要テキスト…
検索結果 5
www.example5.com – 概要テキスト…
検索結果 6
www.example6.com – 概要テキスト…
Yes
No
特許の要諦:複数ソースの統合 • 需要に基づく項目順位付け • KGの確率融合 • クエリ理解からUIへの落とし込み
この特許の骨子は、受信クエリから「事実実体」を見立て、テンプレートに基づくパネルを、検索結果と並置して提示する一連の作法にあります。
請求項の主要部は、検索結果の取得と実体の同定、タイプに応じたテンプレート選択、そして少なくとも二つの異なるリソースから項目を選び出す「内容選定」を定めています。
さらに、選定には実体に関するユーザー検索イベントに基づく順位付けを用いること、パネルが各検索結果より大きな領域を占めうることなど、UI上の優先度づけの考え方もカバーします。図12のフローチャートは、パネル要否の判定からテンプレートの適用、項目充填、SERPへの合成までの処理順を視覚化し、図8〜11は具体的な画面バリエーションを例示しています。
ここでは「複数ソースの統合」と「需要に基づく項目順位付け」が、ナレッジグラフの確率融合と前段のクエリ理解をUIへ落とす要諦だと読み取れます。
請求項 について (a) クエリ群の特定
特定の実体(factual entity)を参照する受信クエリを特定。→ユーザイベント起点 で「何が求められたか」を把握。
(b) リソースの同定
当該クエリに関連する複数リソース を特定。
(c) 検索結果の取得
クエリに応答する検索結果を生成。
(d) 実体タイプの判定
人/場所/作品などタイプ を決める。→テンプレート選択の前提 。
(e) テンプレート選択
タイプ別テンプレート を集合から選ぶ 。
(f) コンテンツ選定
第一ソースの項目+第二ソース(異なる発行者)の項目をクエリで共起した証拠数等に基づき選ぶ(ここが重要:複数ソース統合とランキング規準 )。
(g) パネル生成
テンプレートのプレースホルダに選定項目を充填 。
(h) 表示
SERPの横領域 に検索結果と並置 (面積は各検索結果より大きい、等の従属項)。
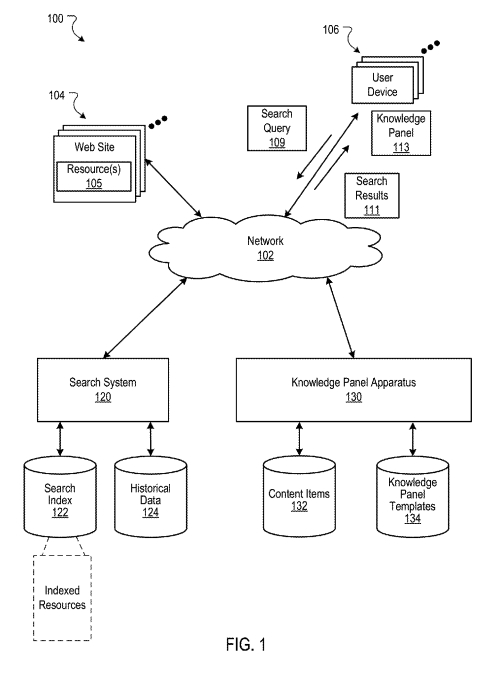
FIG.1
検索システム120とKnowledge Panel Apparatus 130 、Content Items 132 / Templates 134 の分担(収集・整形とUI生成の分離 )。
引用:https://patentimages.storage.googleapis.com/fe/5a/e2/5790e0c808b86e/US9268820.pdf
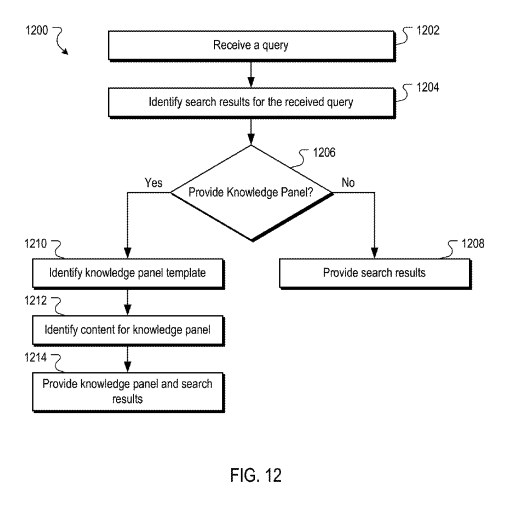
FIG.12
フロー(検索結果識別→パネル要否判定 →テンプレート選択→コンテンツ充填 →SERPに合成 )。実際の運用順序を示す。
引用:https://patentimages.storage.googleapis.com/fe/5a/e2/5790e0c808b86e/US9268820.pdf
FIG.3–11
多様なUIバリエーション(画像枠、ファクト表、株価などウィジェット的要素 )。
情報源の異種性 を前提にランキングで統合 。ユーザクエリの履歴(イベント)を証拠として使うという発想は、Knowledge Vaultの確率融合 (事実信頼度)と相補的。
US 11,720,577 B2
US特許 11,720,577 B2(ナレッジパネルのコンテキスト化)
コンテキスト語を関係シグナルとして解釈し、UI要素を優先順位付け
クエリ入力
エンティティ IDコンテキスト語
例: “アインシュタイン” + “相対性理論”
クエリ
フロントエンド
構文解析・トークン化
初期処理
エンティティ 認識エンジン
E1
E2
E3
パネル
コンテキスト化器
コンテキスト分析
シグナル処理
関係充填器(中間層)
E
E2
関係1
E3
関係2
E4
関係3
グラフパス制約
→ 一次UIシグナル
関係スコアリング
知識エンジン
エンティティ データベース関係グラフストア
ランキングシステム
1. 関係の関連性スコア
2. コンテキスト信号強度
3. エンティティ 接続重み
コンテキスト化されたUIパネル
1. 主要関係要素
高
2. コンテキスト知識要素
中
3. 標準知識要素
低
コア設計思想
• コンテキスト語をエンティティ 間の関係シグナルとして解釈
• グラフパス制約をUI順位付けの一次信号に昇格
• 関係の関連性に基づく動的な優先順位付け
• 関係ベースの知識要素が最高優先度を獲得
データフロー凡例
メイン処理
コンテキストシグナル
関係データ
US 11,720,577 B2
この特許は、クエリに含まれる「コンテキスト語」を関係のシグナルとして解釈し、パネルの中で関係要素を優先的に提示することを権利化しています。
請求項では、エンティティ 識別子と一つ以上のコンテキスト語を受け取り、それらがエンティティ と他の複数エンティティ を結ぶ関係を表していると判定した場合に、関係に紐づく知識要素を選び、ランキングに基づいてUIに配置する、という手順が述べられます。
本文のシステム図は、query front‑end、entity recognition engine、knowledge engine、そしてpanel contextualizerの分業を描き、関係充填の中間層が明確に位置づけられています。ここから、「関係」というグラフ上のパス制約を、UI順位付けの一次信号に昇格させる設計思想が読めます。
請求項 について
(a) 受信リクエスト
エンティティ 識別子1つ以上のコンテキスト語 を含むクエリを受ける。
(b) 関係の同定
そのコンテキスト語が、当該エンティティ と他エンティティ 群を結ぶ関係 を記述している と判定。
(c) UI要素の生成
関係知識要素(relationship knowledge elements)をランキング上位 で生成し、事実(facts)を提示。併せて追加の知識要素 も特定・配置。
(d) 配置
上位に関係要素 を置き、SERP上に提供 (上位/先頭に置く従属項や、ユーザ属性でランク調整する従属項あり)。
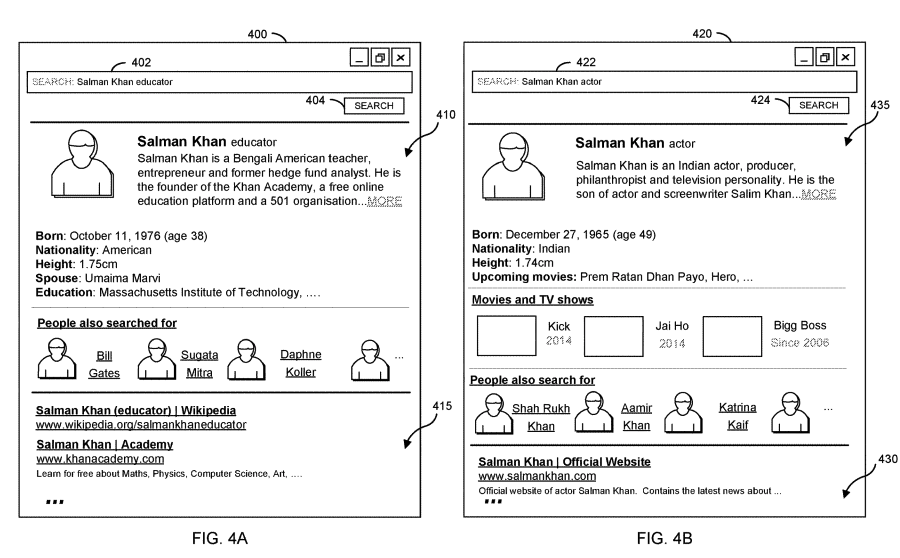
FIG.4A/4B
Salman Khanの二義性 (教育者 vs 俳優)を関係と属性 でコンテキスト化し、関連人物・作品 など関係要素が上位にくる UI。
引用:https://patentimages.storage.googleapis.com/3f/0e/86/cef8bddb72ac1f/US11720577.pdf
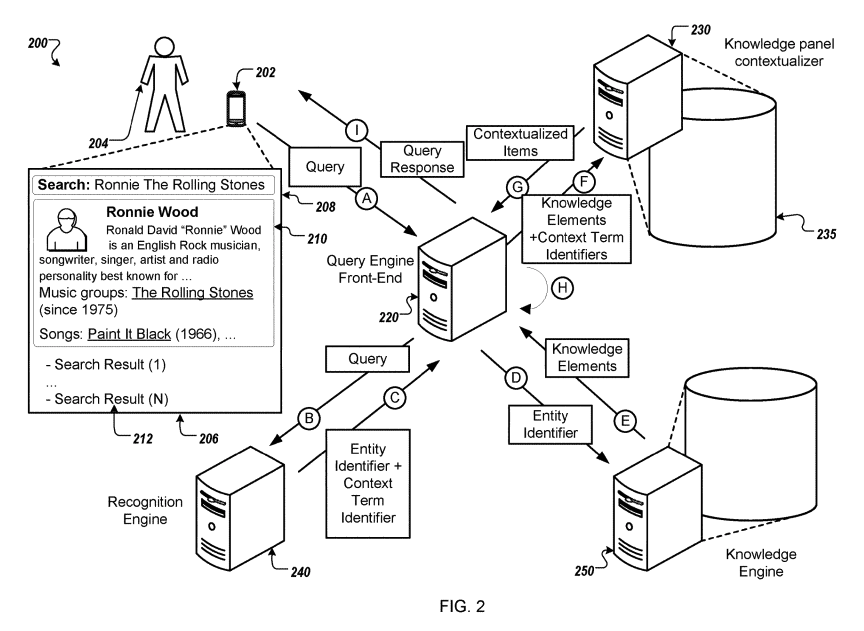
本文FIG.2(システム204–240) query front-end → panel contextualizer → entity recognition engine → knowledge engine の分業。関係充填を担う中間層 が明記される。
引用:https://patentimages.storage.googleapis.com/3f/0e/86/cef8bddb72ac1f/US11720577.pdf
「コンテキスト語=グラフ上のパス制約」として解釈し、関係に沿ったノード群を上位提示 。関係要素の優先配置 は、ユーザが求めるつながりをUIで直接提示 する指針を請求項できちんと権利化している点がポイント。
US 10,055,462 B2
米国特許 10,055,462 B2 (拡張検索クエリシステム)
エンティティ 曖昧性解消とナレッジグラフベースのクエリ拡張アーキテクチャ
クエリ入力処理
元クエリ:
「アインシュタイン 理論」
検出エンティティ :
「アインシュタイン」
[曖昧性:高]
エンティティ 選択インターフェース
アルベルト・アインシュタイン
物理学者 | 相対性理論 | 1879-1955
信頼度: 0.94 | KGノード数: 1,247
アインシュタイン・ブラザーズ
ベーグルチェーン店 | 1995年創業
信頼度: 0.12 | KGノード数: 89
アインシュタイン(単位)
光合成光量子束密度の単位
信頼度: 0.08 | KGノード数: 34
ナレッジグラフナビゲーション&属性抽出
アインシュタイン
相対性理論
0.96
物理学
0.94
ノーベル賞
0.89
理論
0.92
E=mc²
0.91
ドイツ
0.85
1921年
プリンストン
天才
拡張クエリ生成器
生成された拡張クエリ(信頼度順):
「アインシュタイン 理論 相対性理論 物理学 ノーベル賞」
0.95
「アインシュタイン E=mc² 理論 物理学 ドイツ」
0.91
「アインシュタイン ノーベル賞 1921年 相対性理論」
0.88
属性語彙拡充と信頼度学習
動的属性重み調整:
相対性理論:
96%
物理学:
94%
理論:
92%
✓ アクティブラーニング:18,734回反復 | 学習率:α=0.03
拡張検索結果
アインシュタインの特殊相対性理論(1905年)
一致率:97% | 拡張属性:相対性理論、物理学、理論、E=mc²
1921年ノーベル物理学賞 – アルベルト・アインシュタイン
一致率:93% | 拡張属性:ノーベル賞、物理学、光電効果
アインシュタインの一般相対性理論(1915年)
一致率:89% | 拡張属性:重力、時空、相対性理論
ユーザー選択フィードバックループ
システムパフォーマンス指標
曖昧性解消精度:
92.4%
クエリ拡張効果:
+34% CTR
平均応答時間:
287ms
KGカバレッジ:
420万ノード
この特許は、実体参照を含むクエリに対して、まず同名異人などの複数候補を区別した結果を提示し、その結果群から当該エンティティ の属性を抽出して「拡張クエリ」を自動生成し、ユーザーの選択に応じて結果を更新する流れを定義します。
図1と図2は、拡張クエリ生成器を含むシステム構成と、エンティティ 選択パネルを備えたUIの概観を示し、図7〜9は、ナレッジグラフのノードとエッジを辿ってクエリを展開するイメージを提供します。属性語彙の拡充と事実信頼度の学習が背後で効くことで、提示する拡張クエリの質と順序に説得力を与えるという含意が読み取れます。
請求項 について
(a) 受信 エンティティ 参照複数実体に対応 )。
(b) 初期結果 異なる実体を区別 して結果を提示。
(c) 属性抽出 その実体の属性 (人なら「第2代大統領」、映画なら「主演/公開年」など)を抽出。
(d) 追加クエリ生成 (クエリ×実体×属性×ランキング)に基づき拡張クエリ を生成し提示 。
(e) 選択入力→更新 結果を更新 (初期結果にない新結果を含む)。
図面の指差し
FIG.1 Structured Data 104 / Processing 106 / Content 108 からOutput 110 へ(結果と追加クエリの生成器がProcessing 106 )。
引用: https://patentimages.storage.googleapis.com/66/f6/33/74549578b931a4/US10055462.pdf
FIG.2 クエリ→エンティティ 識別パネル (Entity1/2/3)→結果列 のUI。
引用:https://patentimages.storage.googleapis.com/66/f6/33/74549578b931a4/US10055462.pdf
FIG.7–9 ナレッジグラフ断片の可視化 (George Washingtonの属性とタイプ関係、州と都市の関係など)。拡張クエリが辿る属性/関係エッジの絵 として読むと分かりやすい。
これは「質問補助」の特許。ナレッジグラフの 属性/関係を 動的クエリ展開に使い、探索を段階的に深めるUIパターンをカバーする。Biperpedia的な 属性語彙の拡充やKnowledge Vault的 信頼度を背後に置くと、拡張候補の 生成・順位に説得力が出る。
US 9,864,808 B2
米国特許 9,864,808 B2(ナレッジベースエンティティ 検出と曖昧性解消)
Microsoft Technology Licensing, LLC – 検索インデックスへの実体リンク統合システム
処理パイプライン(図1〜3)
図1: クエリ処理
“Harry Shum”
エンティティ 言及検出クエリ解析モジュール
知識リポジトリ
エンティティ データベース
エンティティ
関係性
文脈メタデータ
図2: 候補エンティティ 列挙
Harry Shum(CV研究者)
ID: E-CV-1923
Harry Shum(MS幹部)
ID: E-MSR-2847
文脈特徴
文書コンテキスト分析
クエリ履歴パターン
ユーザー行動シグナル
図3: 曖昧性解消
文脈ベースランキング
E-MSR-2847(Microsoft)
スコア: 0.92
E-CV-1923(研究者)
スコア: 0.31
✓ 選択: E-MSR-2847
検索インデックス
エンティティ ID: E-MSR-2847リンク済み文書: 2,847件
結果比較
エンティティ IDあり精度: 94%
エンティティ IDなし精度: 67%
図4: SERP再構成 – エンティティ 粒度での結果整理
“Harry Shum” の検索結果 – エンティティ ベース文書クラスタリング
Harry Shum(Microsoft幹部)- E-MSR-2847
• Microsoft執行副社長プロフィール
• Microsoft AI&リサーチグループリーダーシップ
• テクノロジー戦略とイノベーション記事
関連性でランク付けされた2,847件の文書
Harry Shum(研究者)- E-CV-1923
• コンピュータビジョン研究論文と出版物
• 学術引用と会議録
• 画像処理とパターン認識研究
関連性スコアが低い1,523件の文書
ランキング
調整
クエリ
列挙
文脈
候補
実体ID
評価
整理
主要イノベーション:
検索・索引付けの側から実体リンクを制度化
• IDベース文書クラスタリング
• KG時代の検索変革
• エンティティ 粒度でのSERP再構成
この特許は、検索と索引付けの側から実体リンクを制度化した位置づけです。クエリに現れる候補エンティティ を知識リポジトリから列挙し、文脈特徴でランキングしたうえで、選択した実体IDを検索インデックスに結びつけ、IDあり・なしの結果を比較しながらランキングを調整するといった、実用的なSERP再構成の骨を与えています。
図1〜3は検出・曖昧性解消・索引までの処理系とパイプライン、図4はHarry Shumに関する同名異人のグルーピング表示を例に、エンティティ 粒度での結果整理を視覚化しています。ナレッジグラフ時代の検索が、IDを介して文書群を再配列しうることを、特許という一次資料で確認できます。
請求項 について
(a) 候補列挙
検索クエリに現れる実体候補 を知識リポジトリ から列挙。
(b) ポテンシャル一致の特定 →(c) ランク付け →(d) 実際に検索に使う実体集合を選択 。
(e) 実体ベース検索 を実行。
(f) 結果ランキング では、エンティティ IDの有無ID付き結果と照合 して並べ替える(実体で束ねてSERPを再構成 )。
FIG.1
Knowledge Repository / Detection / Disambiguation / Indexing / Retrieval / Ranking の構成ブロック。
引用:https://patentimages.storage.googleapis.com/43/e9/62/56908bb9827798/US9864808.pdf
FIG.2
受信→列挙→同定→ランク→選択→実体検索→ランキング→提供 の直列フロー。
引用:https://patentimages.storage.googleapis.com/43/e9/62/56908bb9827798/US9864808.pdf
FIG.3
新規文書からエンティティ 抽出→索引→知識庫更新 (※継続学習)。
引用:https://patentimages.storage.googleapis.com/43/e9/62/56908bb9827798/US9864808.pdf
FIG.4
Harry Shumの二義性 をグルーピング表示 。SERPレベルでの曖昧性解消 を視覚化。
引用:https://patentimages.storage.googleapis.com/43/e9/62/56908bb9827798/US9864808.pdf
NERはテンプレート抽出+統計モデル(CRFなど)のハイブリッド。別サイトにある正解ページとの近接度でエンティティ を決める考えも述べられる。IDで検索インデックスを拡張することでエンティティ 粒度の検索・リランキング を可能にする。
ナレッジグラフにおける抽出・融合・語彙拡張
ナレッジグラフの実用化を下支えする研究として、Knowledge Vaultは異種抽出器の出力を特徴量化し、既存KBを事前分布に用いながら、事実の正しさを確率として一貫的に推定する方法を提示しました。
これにより、ウェブの長大な尾部にある事実候補を取り込みつつ、誤りに頑健な統合が可能になります。一方、Biperpediaは、クエリストリームやテキストから(クラス, 属性)対を大規模に抽出し、たとえば国に対する首都・GDPのような属性語彙を広げ、拡張クエリや表理解の精度を押し上げる道筋を示しました。
加えて、YAGO2が持つ時空間アンカーの発想は、肩書や所在地など時間依存の属性を扱ううえでの参照点となります。
ナレッジグラフの先行研究が示す考え方の枠組み
抽出・融合・語彙拡張
ナレッジグラフ
実用化基盤
Practical Foundation
Knowledge Vault
異種抽出器の出力を特徴量化
• Multiple extractor outputs as features
既存KBを事前分布として活用
• Existing KB as prior distribution
ウェブ長大尾部の事実を誤りに頑健に統合
Biperpedia
クエリストリームから(クラス,属性)対を抽出
• Extract (class, attribute) pairs at scale
属性語彙の大規模拡張
• Example: Country → Capital, GDP
拡張クエリと表理解の精度向上
YAGO2
時空間アンカーの発想を提供
• Temporal-spatial anchoring concept
時間依存属性の管理
• Positions, locations over time
時間依存属性の参照点として機能
抽出
語彙拡張
融合
スキーマ・ID空間とエコシステム
ウェブ側ではschema.orgが、JSON‑LDやMicrodataでの型・プロパティの表明を標準化し、クローラと抽出器が意味情報を拾いやすくします。これはナレッジグラフの同一性解決やスキーマ整合を助ける前提条件です。
外部知識の面では、FreebaseからWikidataへの移行過程自体が研究として公開され、語彙整合や参照情報の移送方法が議論されています。
さらに、開発者向けには「Knowledge Graph Search API」がエンティティ 検索とJSON‑LD準拠の応答を提供し、企業向けにはGoogle Cloudの「Enterprise Knowledge Graph」が自社データの実体化とナレッジグラフ接続を支援します。これらは公開ナレッジグラフのID空間とアプリケーション実装を橋渡しする実務の手段です。
スキーマ・ID空間とエコシステム(ウェブと企業内の両輪)
ウェブ側
schema.org
型・プロパティの表明を標準化
JSON-LD
Microdata
クローラ
意味情報の収集
抽出器
データ処理
ナレッジグラフ
同一性解決・スキーマ整合
Freebase
(レガシー知識ベース)
Wikidata
(現行知識ベース)
移行
研究として公開
FreebaseからWikidataへの移行過程
語彙整合・参照情報移送方法の議論
企業側
Knowledge Graph Search API
開発者向け
エンティティ 検索
Entity Search
JSON-LD準拠応答
Compliant Response
Google Cloud
Enterprise Knowledge Graph
企業向け
自社データの実体化
Data Materialization
KG接続支援
KG Connection Support
アプリケーション実装
実務への適用
統合データ基盤との連携
Integration with Data Platform
橋渡し
公開KGのID空間と
アプリケーション実装を
接続する
実務の手段
ナレッジグラフの実装上の留意点
(1)情報源の多元性
Googleはナレッジグラフの情報源にウェブ上の資料・オープンデータ・ライセンスDB を併用と明言。出典の多様性+確率的融合 が品質の要。
(2)オープンエコシステム schema.orgでウェブ側が意味を表明 、Wikidata移行でコミュニティ主導の更新 を取り込む設計思想。
(3)可観測な表層 パネルの項目選定 や画像選択 、関連検索 などUI上の挙動は特許で具体化。需要(検索ログ)と文脈 でダイナミックに変わる。
(4)API連携 公開APIはエンティティ 解決注釈付け の実務に利用可能。クラウド製品群(Enterprise KG)で企業内データ と公開 ナレッジグラフの接続も可能。
(5)評価設計
トリプル正確度、出典カバレッジ、エッジ整合性(型制約違反検出)、時間整合(有効期間t)の多目的最適化 。(時間的整合は公開文献での明示は限定的だが、現実世界の属性は時間依存であるため、実務では重要な拡張と考えられる。)
(6)頑健性 誤情報・新語・同名異人 への対応は、多層確率モデル(KBT) +言語・リンク・テーブル等のマルチモーダル特徴 で軽減。
(7)次の一手 近年はGraph Embedding や大規模言語モデル(LLM )× ナレッジグラフのNeuro‑Symbolic 統合が活発。公開特許・論文の範囲でも、文脈適応 ・生成的拡張 ・対話課題 への接続が示唆されます(例:文脈最適化特許)。
ナレッジグラフの実装上の留意点
Implementation Considerations and Current State
ナレッジグラフ
ナレッジグラフ
情報源の多元性
Information Source Diversity
ウェブ資料
オープンデータ
ライセンスDB
確率的融合による品質確保
オープンエコシステム
Open Ecosystem
schema.org
Wikidata
ウェブ側の意味表明
コミュニティ主導の更新
可観測な表層
Observable Surface Layer
項目選定
画像選択
関連検索
検索ログと文脈による動的変化
API連携
API Integration
エンティティ 解決注釈付け
Enterprise KG による企業データ統合
多元的情報源
開放的設計
動的UI
実装連携
ナレッジグラフは「固定の正解表」ではなく、需要と文脈で動く知識
ナレッジグラフ(動的知識システムの実装)
需要と文脈で変化する知識の表現 — 固定の正解表からの脱却
従来型アプローチ
固定の正解表
ナレッジグラフ
動的システムコア
ユーザー
検索イベント
項目ランク付け
関係要素抽出
拡張クエリ探索
文脈と需要
確率モデル基盤
抽出器精度・ソース信頼度管理
UI表示
事実の集合
日々更新
2012
導入理念
2020
規模・情報源明示
動的性の発展と実装
システム特性
• 需要応答型
• 文脈依存処理
• 継続的更新
• 確率的管理
• 動的ランキング
ここまでの一次資料から見えてくるのは、ナレッジグラフが固定の正解表ではなく、需要と文脈で見せ方が変わる動的システムだという点です。ユーザーの検索イベントを信号として項目をランク付けし、関係語を手がかりに関係要素を前面に押し出し、拡張クエリで探索を深める、こうした設計判断は、請求項の言葉で具体化されています。
裏では抽出器の精度やソースの信頼度が確率モデルで管理され、最終的にUIに現れる事実の集合を日々更新していきます。2012年の導入時の理念と、2020年の規模・情報源の明示は、この動的性を裏づけています。
ナレッジグラフ研究・実装
研究/実装に役立つ視点
ナレッジ
グラフ
評価設計
多目的最適化
トリプル
正確度
出典
カバレッジ
エッジ
整合性
時間整合
(有効期間t)
型制約違反検出
時間依存属性の実務的重要性
頑健性
多層確率モデル(KBT)
誤情報
新語
同名異人
マルチモーダル特徴
言語・リンク・テーブル
次の一手
Neuro-Symbolic 統合
Graph
Embedding
LLM ×ナレッジグラフ
文脈適応・生成的拡張・対話課題への接続
公開特許・論文での実装示唆(例:文脈最適化特許)
ナレッジグラフで誤解しやすい点
Featured Snippet ≠ ナレッジグラフ スニペットは文書抽出に近く、ナレッジグラフの確定ファクト とは別系統(ただしナレッジグラフの理解が表示戦略に影響することはあり得る)。
「正解表」ではない ナレッジグラフは確率的・動的 。需要・文脈・信頼度 で提示内容が変動する設計が特許に明記。
全面自動ではない 抽出・融合は大規模自動だが、オープンKB やライセンスDB 由来の人手品質 が重要な土台。
ナレッジグラフで誤解しやすい点
Common Misconceptions about Knowledge Graph
1
Featured Snippet ≠
ナレッジグラフ
スニペットは文書抽出に近く、
ナレッジグラフの
確定ファクト
とは別系統
(表示戦略への影響はあり得る)
2
「正解表」ではない
ナレッジグラフは
確率的・動的
需要
文脈
信頼度
で提示内容が変動する設計
(特許に明記)
3
全面自動ではない
抽出・融合は大規模自動だが、
オープンKB
や
ライセンスDB
由来の
人手品質
が重要な土台
Knowledge
Graph
文書抽出
確率的
人機協働
需要
文脈
信頼度
確率的・動的・人機協働による知識構造化システム
Probabilistic, Dynamic, Human-Machine Collaborative Knowledge System
IR×NLP×UIの統合としてのナレッジグラフ
Googleのナレッジグラフは、(i)エンティティ 検出と曖昧性解消でクエリをグラフ世界へ投影し、(ii)確率的融合でソース横断の事実を選別・更新し、(iii)テンプレートと文脈最適化でナレッジパネルを合成し、(iv)拡張クエリでユーザーの意図解像度を引き上げる、というIR・NLP・UIの統合システムとして設計されています。
その全体像は、2012年の公式ブログと2020年の再解説、そしてここで逐条解説した特許群により、理念・数理・表示の三層で読み解けます。研究論文の枠組み(Knowledge VaultやKBT、Biperpedia、YAGO2)は、この統合の内側で「何を信じ、どう見せるか」を学習的に支える基礎になっています。
Googleのナレッジグラフは、オープン/ライセンス知識+ウェブ自動抽出 を確率的に融合 し、クエリ時の文脈 で最適に提示 するための超大規模・動的知識基盤 です。理念としての「things, not strings」を、実体解決 ・データ融合 ・表示最適化 という工学の積み木で積み上げたシステムと捉えるのが本質です。
IR × NLP × UI の統合としての
ナレッジグラフ
Knowledge
Graph
IR
情報検索
NLP
自然言語処理
UI
ユーザーインターフェース
PROCESS FLOW
1
エンティティ 検出曖昧性解消
クエリ→グラフ投影
2
確率的融合
ソース横断
事実選別・更新
3
テンプレート
文脈最適化
ナレッジパネル合成
4
拡張クエリ
意図解像度
ユーザー意図引き上げ
三層アーキテクチャ
理念
2012 公式ブログ
数理
特許群逐条解説
表示
2020 再解説
研究論文フレームワーク
Knowledge Vault • KBT • Biperpedia • YAGO2
「何を信じ、どう見せるか」を学習的に支える基礎